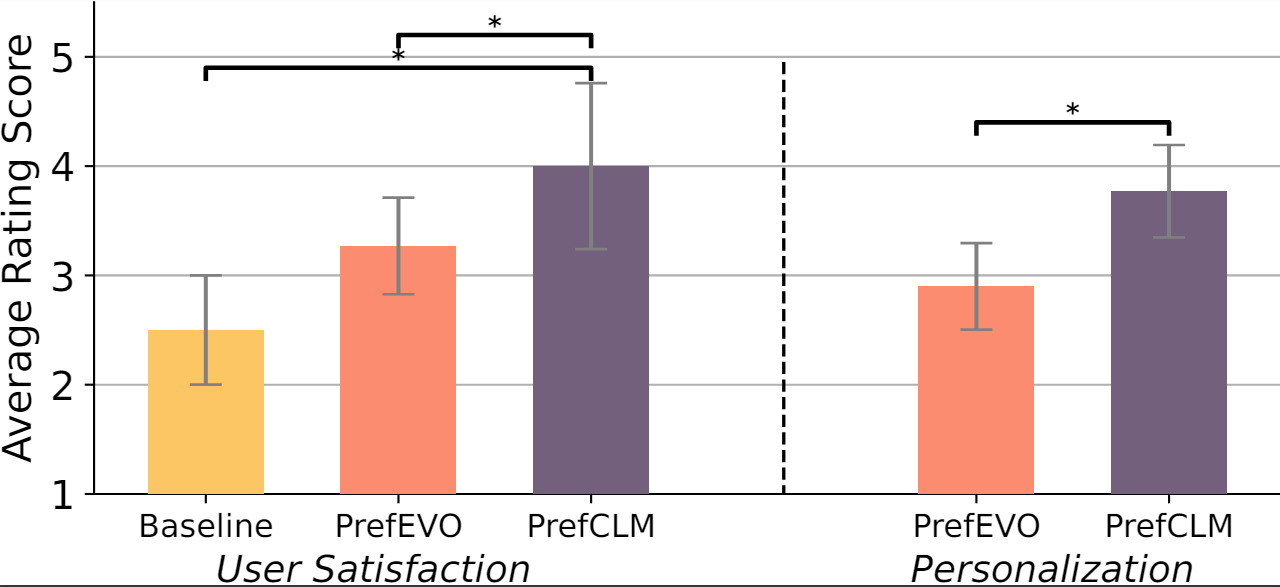
Experiments & Results: General RL Tasks
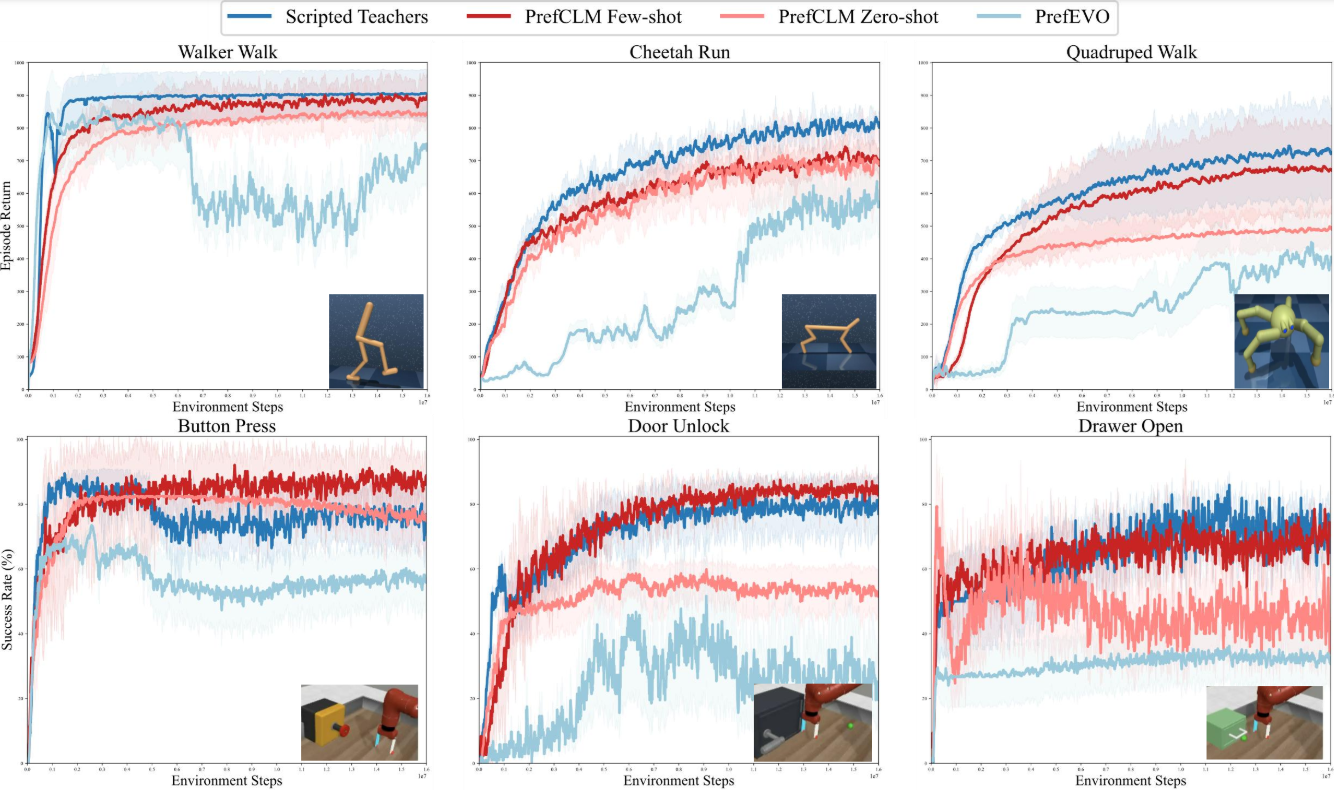
We tested PrefCLM on a range of standard RL benchmarks, including locomotion tasks (Walker, Cheetah, Quadruped) from the DeepMind Control Suite and manipulation tasks (Button Press, Door Unlock, Drawer Open) from Meta-World. We compared our method against two baselines: expert-tuned Scripted Teachers and PrefEVO, a single-LLM approach adapted from recent work on reward design.
Results from our analysis showed the following key findings:
- PrefCLM achieved comparable or superior performance to expert-tuned Scripted Teachers across most tasks
- PrefCLM outperformed PrefEVO, demonstrating the benefits of its crowdsourcing approach
- Few-shot mode of PrefCLM showed advantages over zero-shot, especially for complex tasks
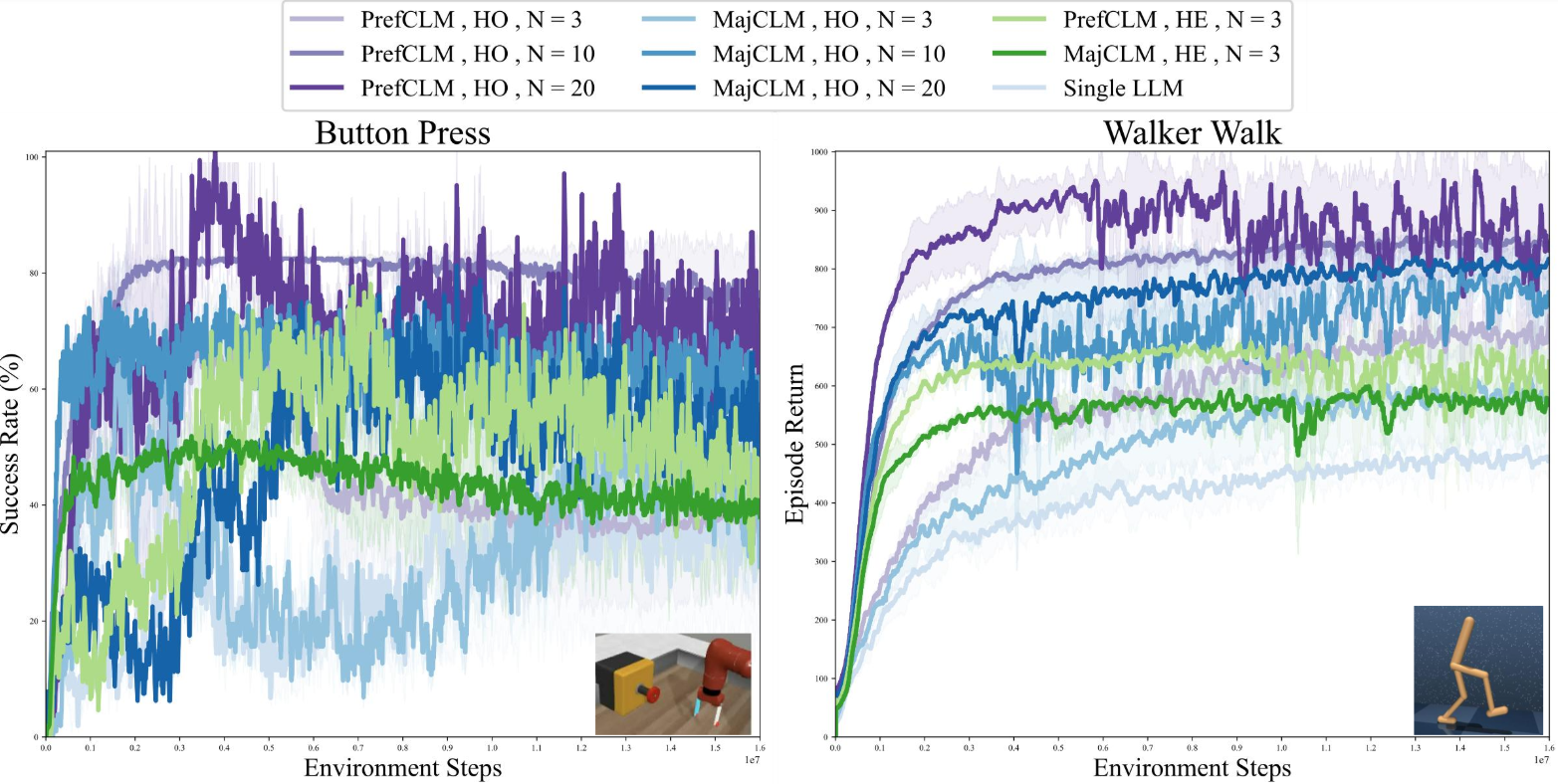
- Ablation studies revealed benefits of increasing crowd size and using DST fusion over majority voting
This visual comparison below highlights how PrefCLM leads to more natural and efficient robot behaviors compared to traditional methods. Locomotion behaviors learned by Scripted Teachers (left) and PrefCLM (right) on the Cheetah Run task.
We conducted ablation studies to investigate the impact of crowdsourcing and DST fusion mechanisms within our framework. The ablation results below demonstrate the benefits of our crowdsourcing approach and the effectiveness of DST fusion in managing complexities and conflicts among LLM agents.
![<b>Walker Task Evaluation Functions:</b> <br>
<span style="font-size: 0.8em; line-height: 30px;"> These functions evaluate the walkers performance based on stability, efficiency, and goal achievement.</span><br><br>
[sep]
assets/rlhf_rewards/walker_task.txt](videos/placeholder/walker_task.png)
![<b>Button Press Task Evaluation Functions:</b> <br>
<span style="font-size: 0.8em; line-height: 30px;">These functions evaluate the robots performance in pressing a button, considering factors like proximity, force applied, and task completion.</span><br><br>
[sep]
assets/rlhf_rewards/button_task.txt](videos/placeholder/button_task.png)